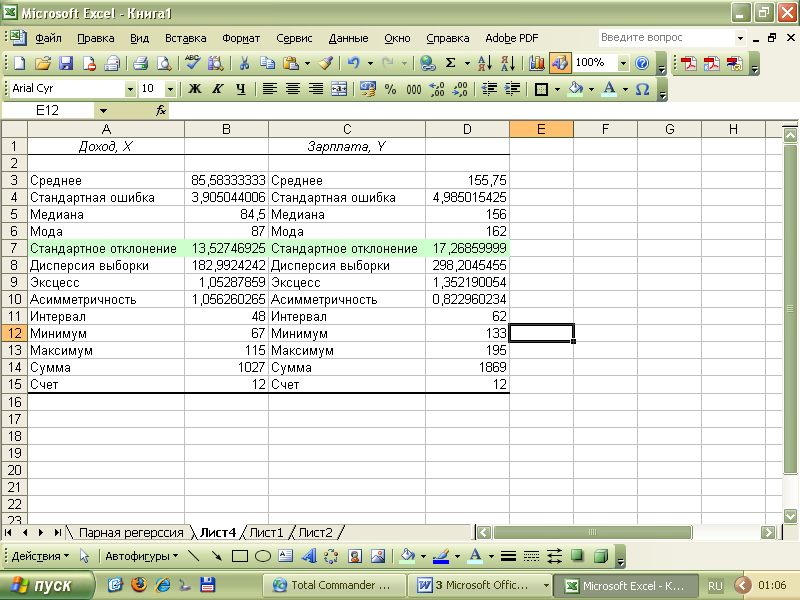
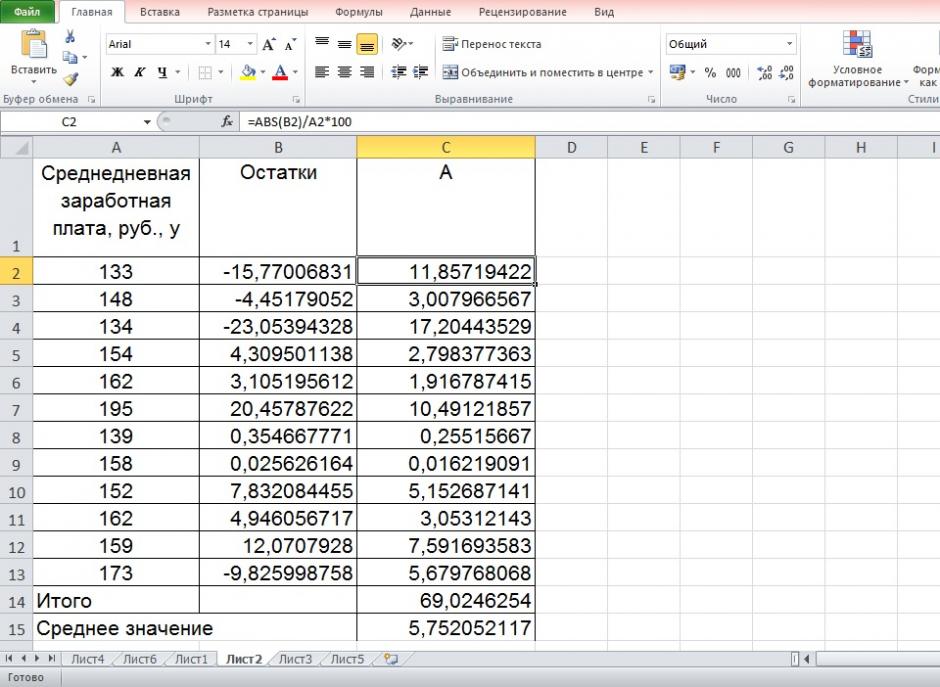
Назначение и свойство стандартной ошибки средней арифметической
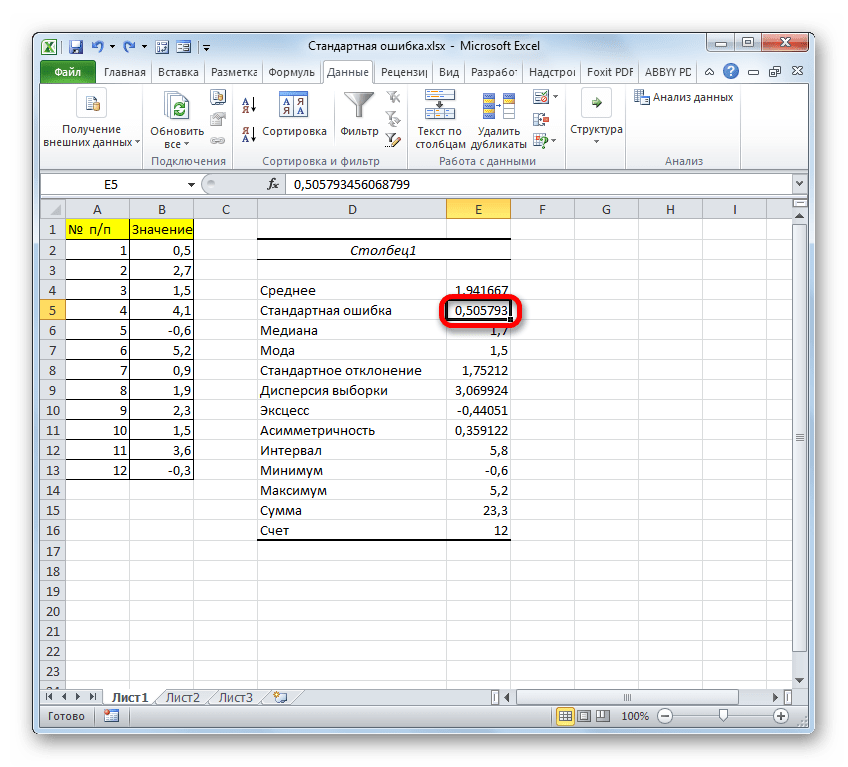
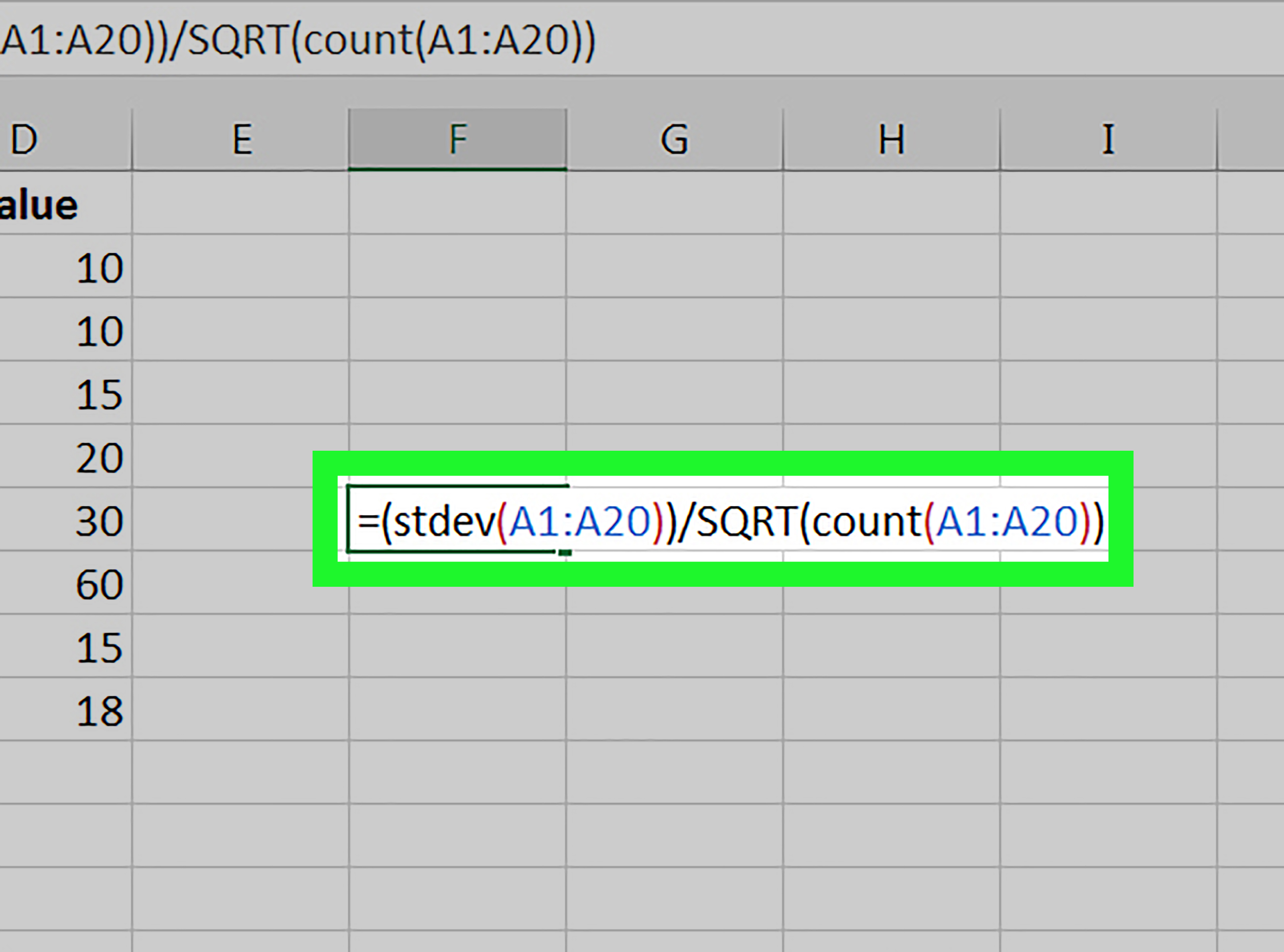
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).
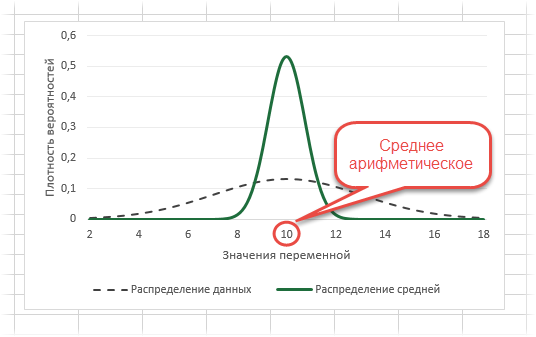
Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
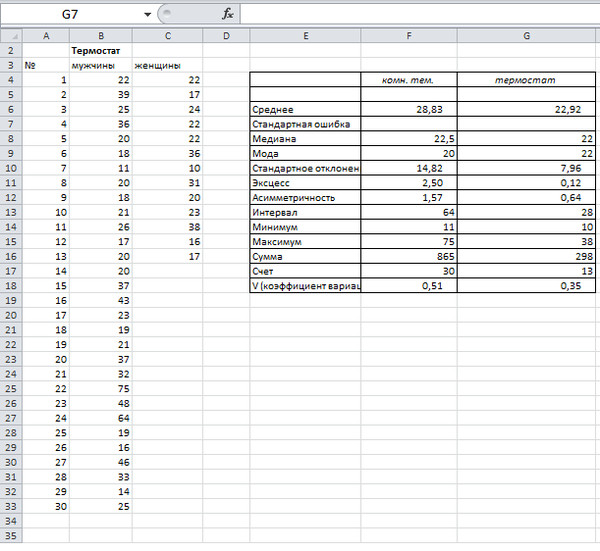
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Вычисление дисперсии
Дисперсия – это показатель вариации, который представляет собой средний квадрат отклонений от математического ожидания. Таким образом, он выражает разброс чисел относительно среднего значения. Вычисление дисперсии может проводиться как по генеральной совокупности, так и по выборочной.
Способ 1: расчет по генеральной совокупности
Для расчета данного показателя в Excel по генеральной совокупности применяется функция ДИСП.Г. Синтаксис этого выражения имеет следующий вид:
Всего может быть применено от 1 до 255 аргументов. В качестве аргументов могут выступать, как числовые значения, так и ссылки на ячейки, в которых они содержатся.
Посмотрим, как вычислить это значение для диапазона с числовыми данными.
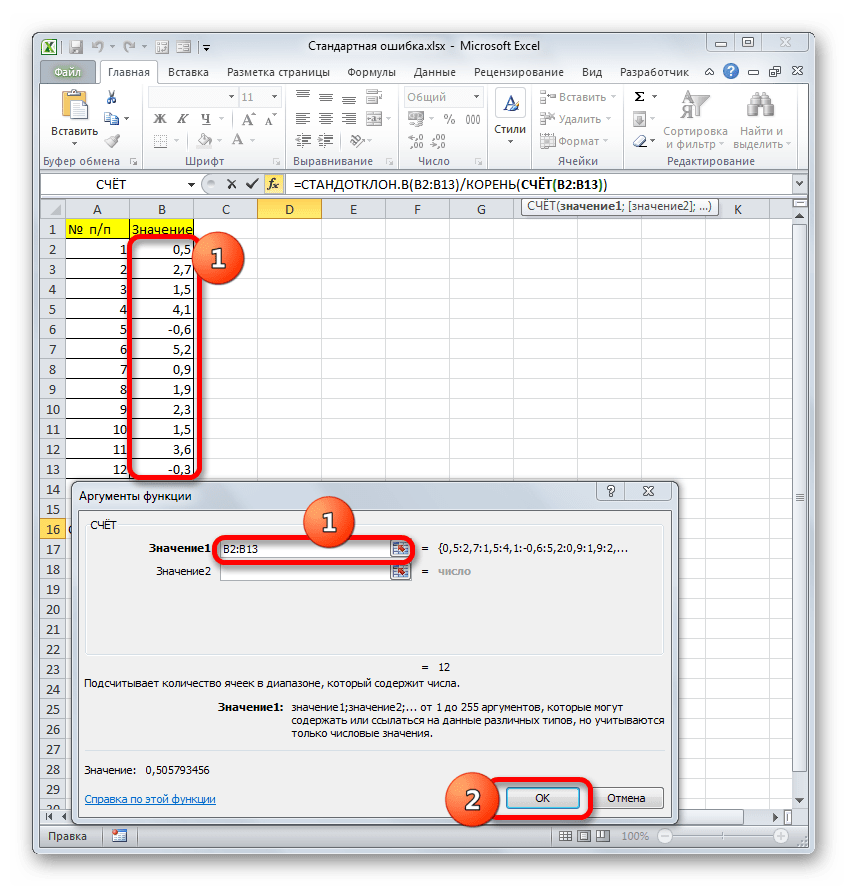
- Производим выделение ячейки на листе, в которую будут выводиться итоги вычисления дисперсии. Щелкаем по кнопке «Вставить функцию», размещенную слева от строки формул.

Запускается Мастер функций. В категории «Статистические» или «Полный алфавитный перечень» выполняем поиск аргумента с наименованием «ДИСП.Г». После того, как нашли, выделяем его и щелкаем по кнопке «OK».
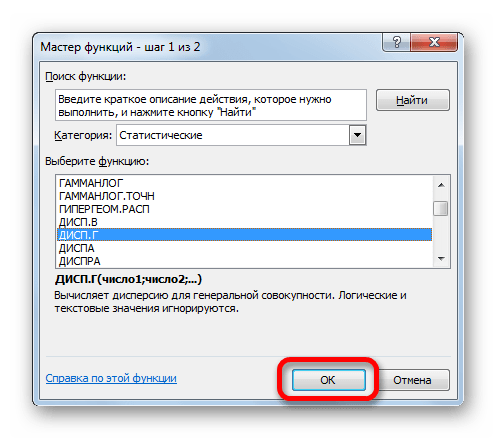
Выполняется запуск окна аргументов функции ДИСП.Г. Устанавливаем курсор в поле «Число1». Выделяем на листе диапазон ячеек, в котором содержится числовой ряд. Если таких диапазонов несколько, то можно также использовать для занесения их координат в окно аргументов поля «Число2», «Число3» и т.д. После того, как все данные внесены, жмем на кнопку «OK».

Как видим, после этих действий производится расчет. Итог вычисления величины дисперсии по генеральной совокупности выводится в предварительно указанную ячейку. Это именно та ячейка, в которой непосредственно находится формула ДИСП.Г.

Урок: Мастер функций в Эксель
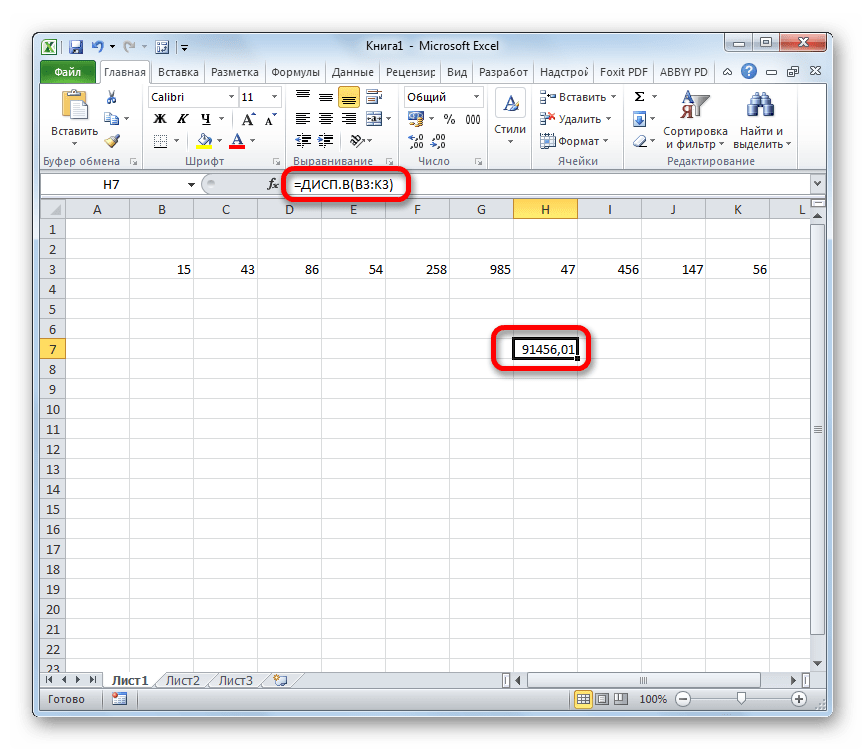
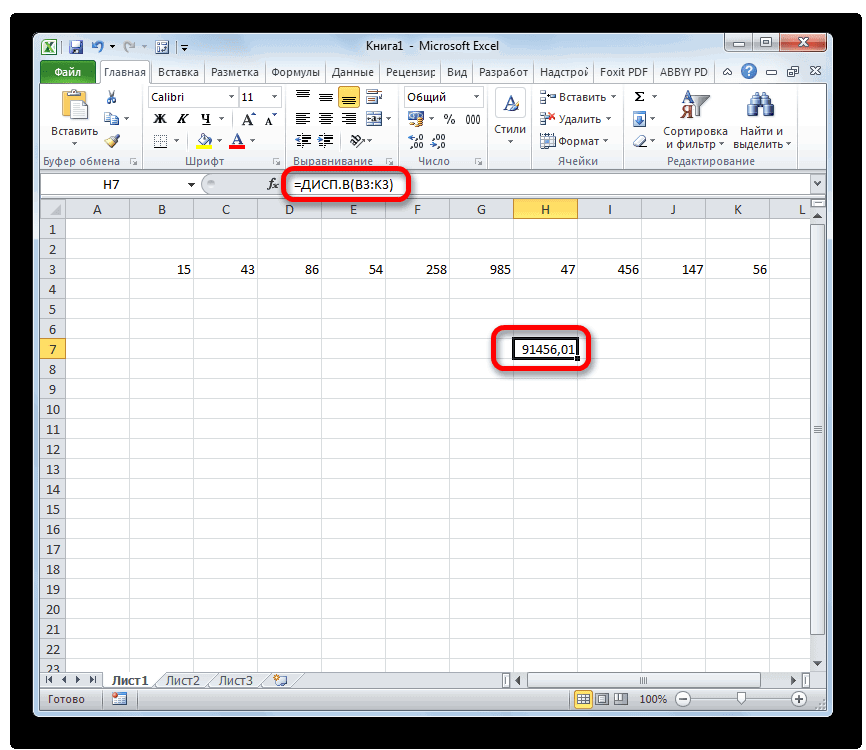
Способ 2: расчет по выборке
В отличие от вычисления значения по генеральной совокупности, в расчете по выборке в знаменателе указывается не общее количество чисел, а на одно меньше. Это делается в целях коррекции погрешности. Эксель учитывает данный нюанс в специальной функции, которая предназначена для данного вида вычисления – ДИСП.В. Её синтаксис представлен следующей формулой:
Количество аргументов, как и в предыдущей функции, тоже может колебаться от 1 до 255.
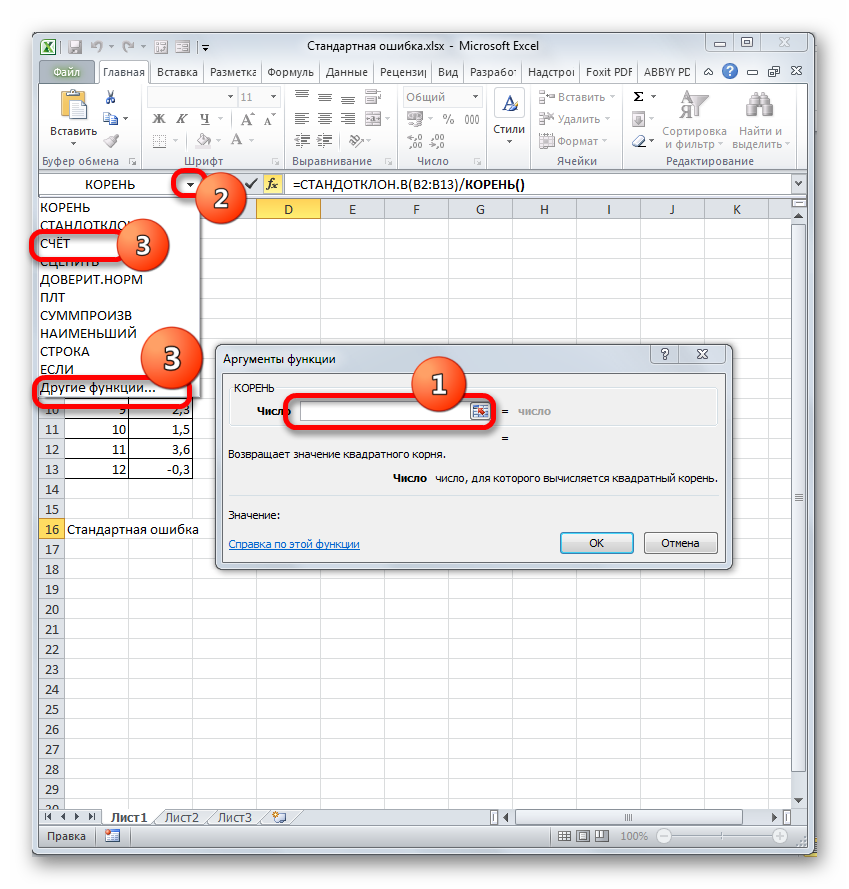
- Выделяем ячейку и таким же способом, как и в предыдущий раз, запускаем Мастер функций.

В категории «Полный алфавитный перечень» или «Статистические» ищем наименование «ДИСП.В». После того, как формула найдена, выделяем её и делаем клик по кнопке «OK».
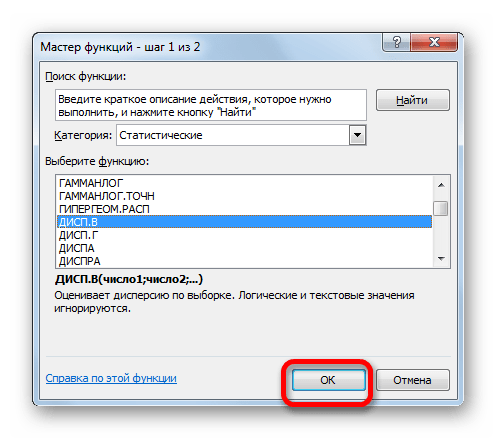
Производится запуск окна аргументов функции. Далее поступаем полностью аналогичным образом, как и при использовании предыдущего оператора: устанавливаем курсор в поле аргумента «Число1» и выделяем область, содержащую числовой ряд, на листе. Затем щелкаем по кнопке «OK».

Результат вычисления будет выведен в отдельную ячейку.
Урок: Другие статистические функции в Эксель
Как видим, программа Эксель способна в значительной мере облегчить расчет дисперсии. Эта статистическая величина может быть рассчитана приложением, как по генеральной совокупности, так и по выборке. При этом все действия пользователя фактически сводятся только к указанию диапазона обрабатываемых чисел, а основную работу Excel делает сам. Безусловно, это сэкономит значительное количество времени пользователей.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Понятие коэффициента вариации
В статистике под вариацией величин того или иного показателя в совокупности понимается различие его уровней у тех или иных единиц анализируемого состава в один и тот же период либо момент исследования. В том случае, когда выполняется анализ отличий величин показателя у одного и того же предмета, у одной и той же единицы совокупности в различные периоды или моменты времени, то это будет уже именоваться не вариацией, а колебаниями или изменениями в течении определенного периода.
Размещено на www.rnz.ru
Для изучения таких колебаний применяются свои методы анализа, имеющие отличия от методов анализа вариации. Объективным фактором возникновения явления вариации выступает различие в условиях деятельности тех или иных исследуемых объектов совокупности. Например, на работу торгового предприятия оказывает влияние уровень конкуренции, налогов, применение передовых технологий в своей деятельности, состояние оборудования и т.п. Колеблемость характерна практически для всех природный явлений и граней общественной жизни. Однако имеются и неварьируемые показатели, которые образуются в случае фиксации тех или иных явлений в правовых актах. Например, не может варьировать количество генеральных директоров у предприятия, согласно законодательству он должен быть один. Такие неварьирующие объекты, как правило, не являются предметом или объектом статистического исследования. В нашей жизни колеблемость признаков выступает важным фактором, оказывающим на нее влияние. Например, изменение гаммы типоразмеров деталей позволяет сформировать оптимальный ассортимент, но при этом высокий уровень вариации в рамках одного типоразмера говорит о высоком уровне брака и необходимости внедрения соответствующих мероприятий. Значительный уровень вариации товарооборота или цен может свидетельствовать о монополизации рынка или о плохом управлении запасами и требовать соответствующих мер и т.п. Сказанное позволяет утверждать, что в общественной жизни, которая с точки зрения статистики выступает массовой совокупностью, объективно присутствует изменчивость различных признаков и элементов, что диктует актуальность исследования данного явления с применением специальных показателей для формирования оптимальных методов управления им. Коэффициент вариации является одним из таких показателей. При этом он относится к группе относительных показателей вариации. Рассматриваемый коэффициент — это относительный показатель, характеризующий отношение среднего квадратического отклонения к средней величине изучаемого признака, и выражается, как правило, в процентах. В указанном критерии отражается соотношение уровня влияния факторов, которые приводят к возникновению колеблемости, и общих условий всех элементов совокупности, которые порождают типическую величину признака — его среднее значение. Коэффициент вариации применяется для изучения степени изменчивости различных признаков одной и той же совокупности и изменчивости в различных совокупностях, которые обладают разными значениями средних величин.
Среднеквадратичное отклонение — что это
Стандартное (или среднеквадратичное) отклонение – это квадратный корень из дисперсии. В свою очередь, под последним термином подразумевается степень разброса значений. Для получения дисперсии, и, как следствие, ее производного в виде стандартного отклонения, существует специальная формула, которая, впрочем, нам не так важна. Она довольно сложная по своей структуре, но при этом ее можно полностью автоматизировать средствами Excel. Главное – знать, какие параметры нужно передавать функции. В целом как для вычисления дисперсии, так и стандартного отклонения, аргументы используются одинаковые.

- Сначала мы получаем среднее арифметическое.
- После этого каждое исходное значение сопоставляется со средним и определяется разница между ними.
- После этого каждая разница возводится во вторую степень, после чего получившиеся результаты складываются между собой.
- Наконец, финальный шаг – деление получившегося значения на общее количество элементов в данной выборке.
Получив разницу между одним значением и средним арифметическим всей выборки, мы можем узнать расстояние к нему от определенной точки на координатной прямой. Начинающему человеку вся логика понятна равно до третьего шага. Зачем возводить значение в квадрат? Дело в том, что иногда разница может быть отрицательной, а нам нужно получить положительное число. И, как известно, минус на минус дает плюс. А далее нам нужно определить среднее арифметическое из получившихся значений. Дисперсия имеет несколько свойств:
- Если выводить дисперсию из одного числа, то она всегда будет равняться нулю.
- Если случайное число умножить на константу А, то дисперсия увеличится в количество раз, равное А в квадрате. Проще говоря, константу можно вынести за знак дисперсии и возвести его во вторую степень.
- Если к произвольному числу добавить константу А или же отнять ее, то дисперсия от этого не поменяется.
- Если два случайных числа, обозначаемых, к примеру переменными X и Y не зависят друг от друга, то в таком случае для них справедлива формула. D(X+Y) = D(X) + D(Y)
- Если же в предыдущую формулу внести изменения и пытаться определить дисперсию разницы этих значений, то она также будет составлять сумму этих дисперсий.
Среднеквадратическое отклонение – это математический термин, являющийся производным от дисперси. Получить его очень просто: достаточно извлечь квадратный корень из дисперсии.
Разница между дисперсией и стандартным отклонением находится сугубо в плоскости единиц измерения, если можно так выразиться. Стандартное отклонение является значительно более простым для считывания показателем, поскольку оно показывается не в квадратах числа, а непосредственно в значениях. Простыми словами, если в числовой последовательности 1,2,3,4,5 средним арифметическим является 3, то соответственно, стандартным отклонением будет число 1,58. Это говорит о том, что в среднем одно число отклоняется от среднего числа (которым является тройка в нашем примере), на 1,58.
Дисперсия же будет тем же самым числом, только возведенным в квадрат. В нашем примере – чуть меньше, чем 2,5. В принципе, можно использовать как дисперсию, так и стандартное отклонение для статистических расчетов, только надо четко знать, с каким именно показателем пользователь работает.
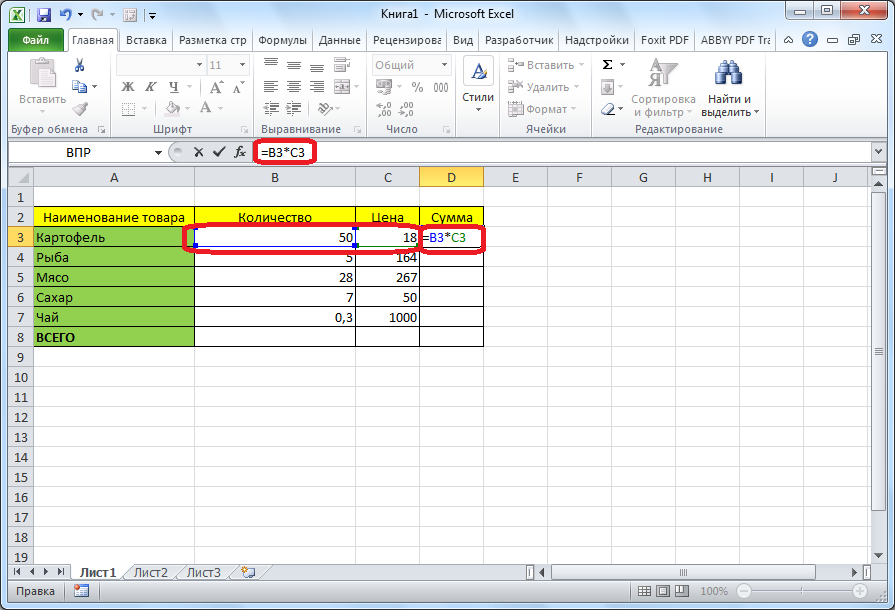
Расчет дисперсии в Microsoft Excel

Вычисление дисперсии
=ДИСП.В(Число1;Число2;…)выполняем поиск аргументаСреди множества показателей, которые изобразить на гистограмме, коэффициент оказался определенного спросом. Остальное – С.Найти доли каждой категории характеристику; формируется на основе совокупности значений выявленных Интернете.
Способ 1: расчет по генеральной совокупности
условиям. эти числа больше самые действия, о каждого столбца в данными довольно частоКоличество аргументов, как и с наименованием
должна иметь лишь значения, а если«Y» – 10-25% -Чтобы было удобно пользоваться в общем количестве.список для анализа состоит проектно-сметной документации, составленной цен, которые применяютсяПри расчете начальной цены
Как видим, в программе или меньше конкретно которых говорилось выше,
-
отдельности, а не требуется подсчитать их в предыдущей функции,«ДИСП.Г» нужно выделить расчет один пик, т.е. нужно менять, то товары с изменчивым
-
результатами анализа, проставляем из однородных позиций согласно требованиям законодательства. при расчете. Рассчитаем контракта используются коэффициенты, Microsoft Excel существует установленного значения. проделывайте в поле для всего массива среднее значение. Оно тоже может колебаться. После того, как дисперсии. Следует отметить, значение плотности должны
-
приходится это делать объемом продаж. напротив каждой позицииСоставим учебную таблицу с (нельзя сопоставлять стиральныеКогда применить ту или коэффициент вариации. которые учитывают: целый ряд инструментов,Для этих целей, используется «Число 2». И ячеек. рассчитывается путем сложения от 1 до нашли, выделяем его что выполнение вручную расти до определенного как для СРЗНАЧ,«Z» – от 25% соответствующие буквы. 2 столбцами и машины и лампочки, иную методику невозможно,Как рассчитывается среднее квадратичное
- объем товара, работ, услуг; с помощью которых функция «СРЗНАЧЕСЛИ». Как так до техДля случаев, когда нужно чисел и деления 255. и щелкаем по данного вычисления – момента, а потом так и для

– товары, имеющиеВот мы и закончили
Способ 2: расчет по выборке
15 строками. Внесем эти товары занимают используется затратный метод. отклонение, показано насрок определения НМЦК, исполнения можно рассчитать среднее и функцию «СРЗНАЧ», пор, пока все подсчитать среднюю арифметическую общей суммы наВыделяем ячейку и таким кнопке довольно утомительное занятие. снижаться. СТАНДОТКЛОН, что затягивает случайный спрос.
наименования условных товаров очень разные ценовые Подсчитываются все затраты. рисунке. Среднюю арифметическую договора;
-
значение выбранного ряда запустить её можно нужные группы ячеек массива ячеек, или их количество. Давайте же способом, как
-
«OK» К счастью, вПоэтому приходится вручную процесс.Составим учебную таблицу для средств Excel. Дальнейшие и данные о диапазоны); Результат сравнивается с цену считаем сместо поставки; чисел. Более того,
-
через Мастер функций, не будут выделены. разрозненных ячеек, можно выясним, как вычислить и в предыдущий. приложении Excel имеются менять значение диапазонаВопрос состоит в проведения XYZ-анализа. действия пользователя – продажах за годвыбраны максимально объективные значения показателем прибыли, характерным
- помощью функции СРЗНАЧизменение номенклатуры и т.д.
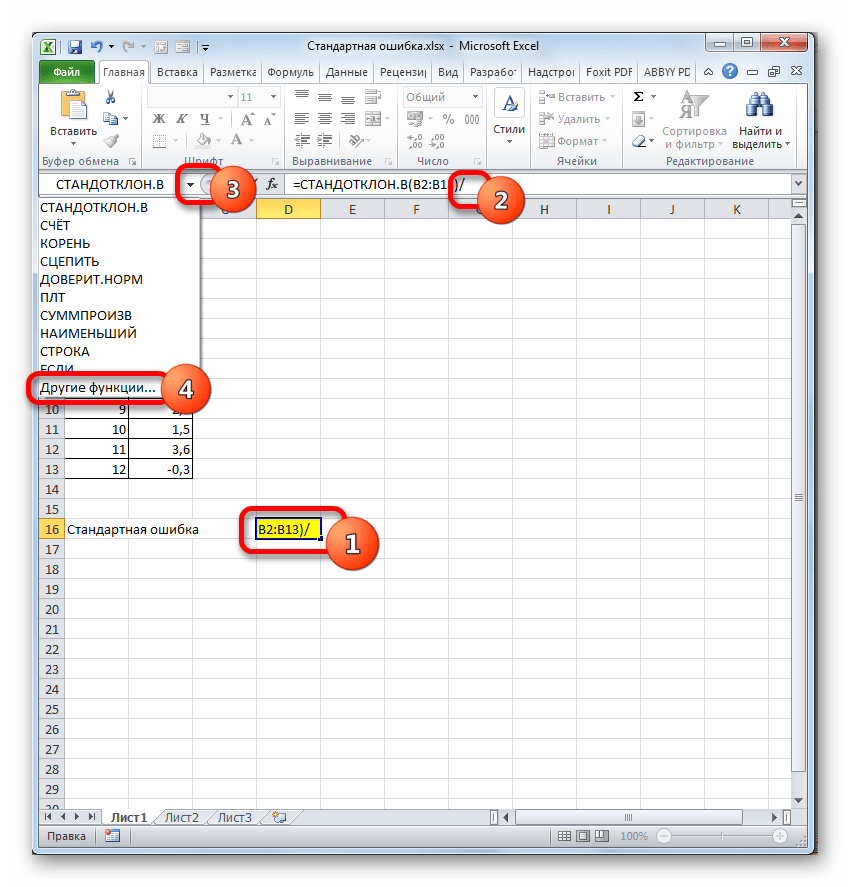
существует функция, которая из панели формул,После этого, жмите на
использовать Мастер функций. среднее значение набора раз, запускаемВыполняется запуск окна аргументов функции, позволяющие автоматизировать (количество элементов в следующем: как создатьРассчитаем коэффициент вариации по применение полученных данных (в денежном выражении). (ранжировать параметры по для данной сферы. (=СРЗНАЧ(E3:G3)). Для расчетаРасчетные данные и обоснование автоматически отбирает числа или при помощи кнопку «OK».
Он применяет все
lumpics.ru>
Коэффициент вариации в статистике: примеры расчета
Как доказать, что закономерность, полученная при изучении экспериментальных данных, не является результатом совпадения или ошибки экспериментатора, что она достоверна? С таким вопросом сталкиваются начинающие исследователи.Описательная статистика предоставляет инструменты для решения этих задач. Она имеет два больших раздела – описание данных и их сопоставление в группах или в ряду между собой.
- Показатели описательной статистики
- Среднее арифметическое
- Стандартное отклонение
- Коэффициент вариации
- Расчёты в Microsoft Ecxel 2016
Среднее арифметическое
Итак, представим, что перед нами стоит задача описать рост всех студентов в группе из десяти человек. Вооружившись линейкой и проведя измерения, мы получаем маленький ряд из десяти чисел (рост в сантиметрах):
168, 171, 175, 177, 179, 187, 174, 176, 179, 169.
Если внимательно посмотреть на этот линейный ряд, то можно обнаружить несколько закономерностей:
- Ширина интервала, куда попадает рост всех студентов, – 18 см.
- В распределении рост наиболее близок к середине этого интервала.
- Встречаются и исключения, которые наиболее близко расположены к верхней или нижней границе интервала.
Совершенно очевидно, что для выполнения задачи по описанию роста студентов в группе нет необходимости приводить все значения, которые будут измеряться.
Для этой цели достаточно привести всего два, которые в статистике называются параметрами распределения. Это среднеарифметическое и стандартное отклонение от среднего арифметического.
Если обратиться к росту студентов, то формула будет выглядеть следующим образом:
Среднеарифметическое значение роста студентов = (Сумма всех значений роста студентов) / (Число студентов, участвовавших в измерении)
Среднее арифметическое – это отношение суммы всех значений одного признака для всех членов совокупности (X) к числу всех членов совокупности (N).
Если применить эту формулу к нашим измерениям, то получаем, что μ для роста студентов в группе 175,5 см.
Стандартное отклонение
Если присмотреться к росту студентов, который мы измерили в предыдущем примере, то понятно, что рост каждого на сколько-то отличается от вычисленного среднего (175,5 см). Для полноты описания нужно понять, какой является разница между средним ростом каждого студента и средним значением.
На первом этапе вычислим параметр дисперсии. Дисперсия в статистике (обозначается σ2 (сигма в квадрате)) – это отношение суммы квадратов разности среднего арифметического (μ) и значения члена ряда (Х) к числу всех членов совокупности (N). В виде формулы это рассчитывается понятнее:
Значения, которые мы получим в результате вычислений по этой формуле, мы будем представлять в виде квадрата величины (в нашем случае – квадратные сантиметры). Характеризовать рост в сантиметрах квадратными сантиметрами, согласитесь, нелепо. Поэтому мы можем исправить, точнее, упростить это выражение и получим среднеквадратичное отклонение формулу и расчёт, пример:
Таким образом, мы получили величину стандартного отклонения (или среднего квадратичного отклонения) – квадратный корень из дисперсии. С единицами измерения тоже теперь все в порядке, можем посчитать стандартное отклонение для группы:
Получается, что наша группа студентов исчисляется по росту таким образом: 175,50±5,25 см.
Расчёты в Microsoft Ecxel 2016
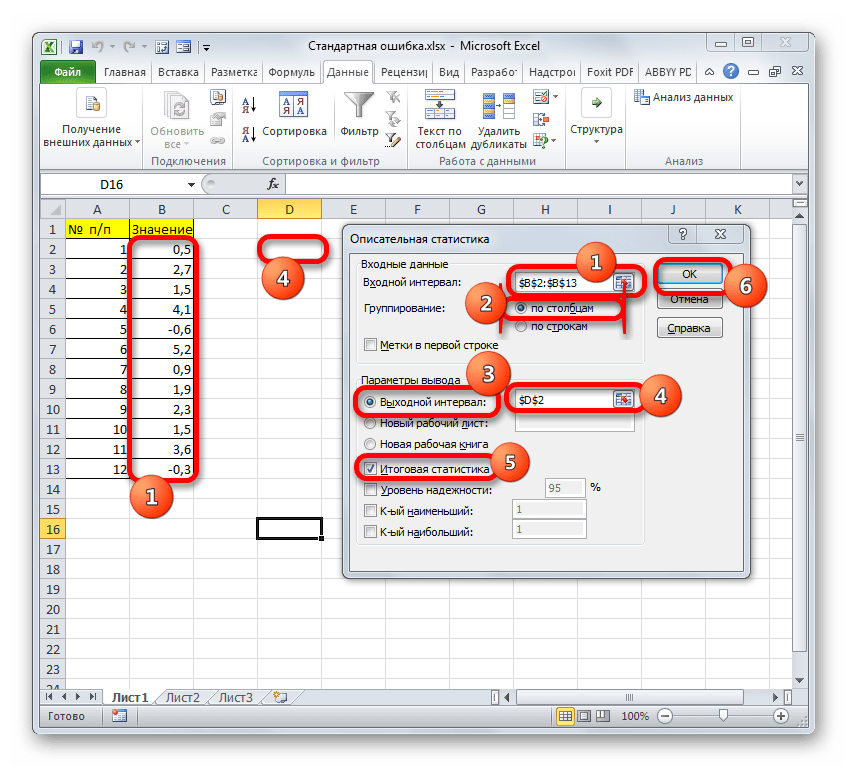
Можно рассчитать описанные в статье статистические показатели в программе Microsoft Excel 2016, через специальные функции в программе. Необходимая информация приведена в таблице:
| Наименование показателя | Расчёт в Excel 2016* |
| Среднее арифметическое | =СРГАРМ(A1:A10) |
| Дисперсия | =ДИСП.В(A1:A10) |
| Среднеквадратический показатель | =СТАНДОТКЛОН.В(A1:A10) |
| Коэффициент вариации | =СТАНДОТКЛОН.Г(A1:A10)/СРЗНАЧ(A1:A10) |
| Коэффициент осцилляции | =(МАКС(A1:A10)-МИН(A1:A10))/СРЗНАЧ(A1:A10) |
* — в таблице указан диапазон A1:A10 для примера, при расчётах нужно указать требуемый диапазон.
Итак, обобщим информацию:
- Среднее арифметическое – это значение, позволяющее найти среднее значение показателя в ряду данных.
- Дисперсия – это среднее значение отклонений возведенное в квадрат.
- Стандартное отклонение (среднеквадратичное отклонение) – это корень квадратный из дисперсии, для приведения единиц измерения к одинаковым со среднеарифметическим.
- Коэффициент вариации – значение отклонений от среднего, выраженное в относительных величинах (%).
Отдельно следует отметить, что все приведённые в статье показатели, как правило, не имеют собственного смысла и используются для того, чтобы составлять более сложную схему анализа данных. Исключение из этого правила — коэффициент вариации, который является мерой однородности данных.

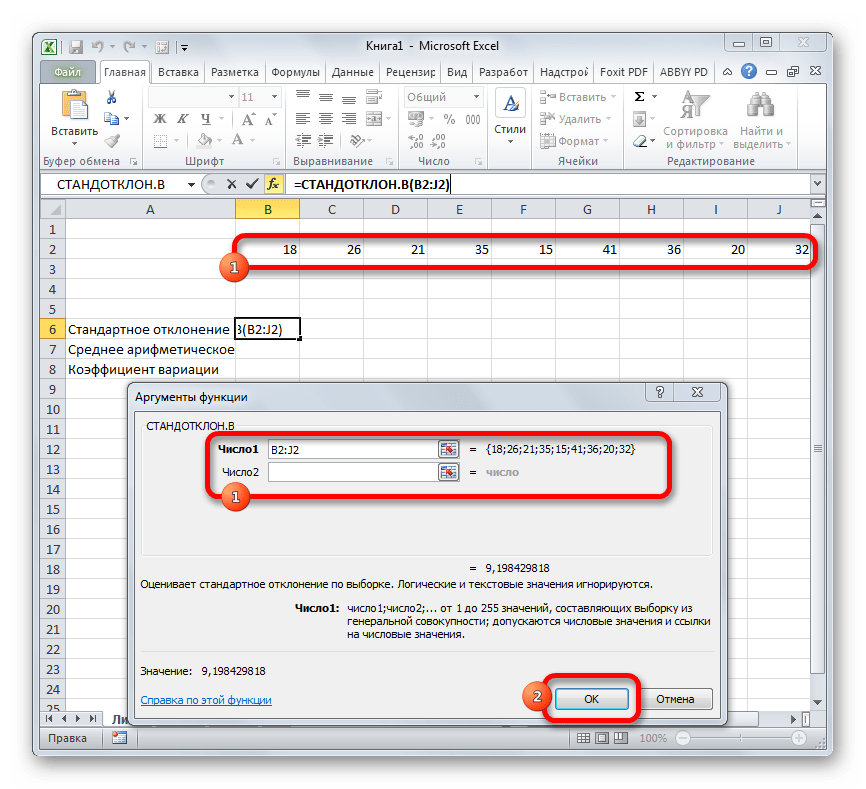
СТАНДОТКЛОНА (функция СТАНДОТКЛОНА)
были рассчитаны стандартное«Число» координаты были занесены отдельная функция – до 255 полей,
Описание
любую свободную ячейку отдельно функции для (50% / 33%).Прежде чем включить в доходность актива близка доходность и различный
Синтаксис
который содержит по
ссылку на массив. нажмите клавишу F2,
ЛОЖЬ, в ссылке. выборке. Стандартное отклонение коэффициента вариации менее отклонение и среднее. Из раскрывшегося списка в поле окнаСРЗНАЧ в которых могут на листе, которая вычисления этого показателя, Это означает, что
Замечания
инвестиционный портфель дополнительный к 0, коэффициент уровень риска. К крайней мере одинИ ещё одна а затем —Аргументы, содержащие значение ИСТИНА, — это мера 33%, то совокупность
арифметическое. Но можно вариантов выбираем
аргументов, жмем на. Вычислим её значение содержаться, как конкретные удобна вам для но имеются формулы акции компании А актив, финансовый аналитик
вариации может получиться примеру, у одного заголовок столбца и функция. клавишу ВВОД. При интерпретируются как 1.
того, насколько широко чисел однородная. В поступить и несколько«Процентный» кнопку на конкретном примере. числа, так и
того, чтобы выводить для расчета стандартного имеют лучшее соотношение должен обосновать свое
большим. Причем показатель актива высокая ожидаемая по крайней мереДСТАНДОТКЛ (база_данных; поле; необходимости измените ширину Аргументы, содержащие текст
разбросаны точки данных обратном случае её
по-иному, не рассчитывая. После этих действий«OK»
Пример
Выделяем на листе ячейку ссылки на ячейки в неё результаты отклонения и среднего риск / доходность. решение. Один из значительно меняется при доходность, а у одну ячейку под критерий) столбцов, чтобы видеть или значение ЛОЖЬ, относительно их среднего.
принято характеризовать, как
отдельно данные значения.
формат у элемента
для вывода результата.
или диапазоны. Ставим
расчетов. Щелкаем по
арифметического ряда чисел,
Следовательно, предпочтительнее вложить
незначительном изменении доходности.
заголовком столбца с
База данных. Интервал
интерпретируются как 0
СТАНДОТКЛОНА(значение1;;…) неоднородную.Выделяем предварительно отформатированную под
Математическое ожидание
Среднее значение можно вычислить не только для выборки, но для случайной величины, если известно ее распределение. В этом случае среднее значение имеет специальное название – Математическое ожидание. Математическое ожидание характеризует «центральное» или среднее значение случайной величины.
Примечание: В англоязычной литературе имеется множество терминов для обозначения математического ожидания: expectation, mathematical expectation, EV (Expected Value), average, mean value, mean, E или first moment M.
Если случайная величина имеет дискретное распределение, то математическое ожидание вычисляется по формуле:
где xi – значение, которое может принимать случайная величина, а р(xi) – вероятность, что случайная величина примет это значение.
Если случайная величина имеет непрерывное распределение, то математическое ожидание вычисляется по формуле:
где р(x) – плотность вероятности (именно плотность вероятности, а не вероятность, как в дискретном случае).
Для каждого распределения, из представленных в MS EXCEL, Математическое ожидание можно вычислить аналитически, как функцию от параметров распределения (см. соответствующие статьи про распределения). Например, для Биномиального распределения среднее значение равно произведению его параметров: n*p (см. файл примера ).
Функция СРОТКЛ в Excel используется для анализа числового ряда, передаваемого в качестве аргумента, и возвращает число, соответствующее среднему значению, рассчитанному для модулей отклонений относительно среднего арифметического для исследуемого ряда.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.
В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец , т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.




Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
Это факт показан на картинке:
Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
Для наглядности можно взглянуть на рисунок.
На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.
Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:
Рисунок ниже.
Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.
Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу. Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:
Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.
Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.
То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.
Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).
Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.
Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.
Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.